![]() Fitting a model to incremental data
Fitting a model to incremental data
|
|
Top Previous Next |
|
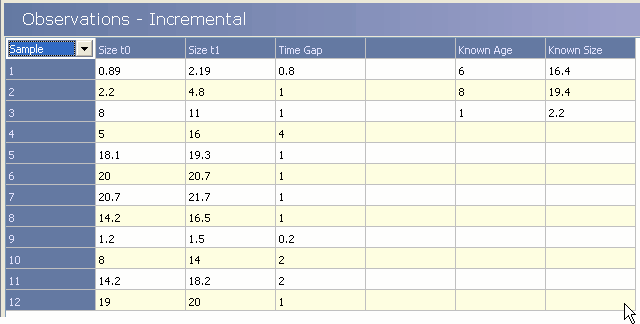
Use File|Open to find and open incremental test Gompertz.csv (saved by default during installation in the folder C:\Program files\GrowthII\GrowthDemoData)
This demonstration data set was generated for demonstration purposes using a Gompertz growth curve with an upper asymptote (L infinity) of 21.9, a growth rate of 0.417 and a point of inflection at t=3.
With the data file loaded you can click on the Incremental Data tab to examine the data set. The first column just gives an identifier for each individual measurement set (it might be a number of name). The Size t0 column gives the initial size measurement for each individual, the Size t1 column gives the size measurement at a later time and the Time Gap column gives the time jump between t1 and t0. For Fabens' 1965 method to work we must also give at least one observation of known size at age and these observations are placed in the Known Age and Known Size columns. (see Entering and Editing Data for information on how to enter your own data)
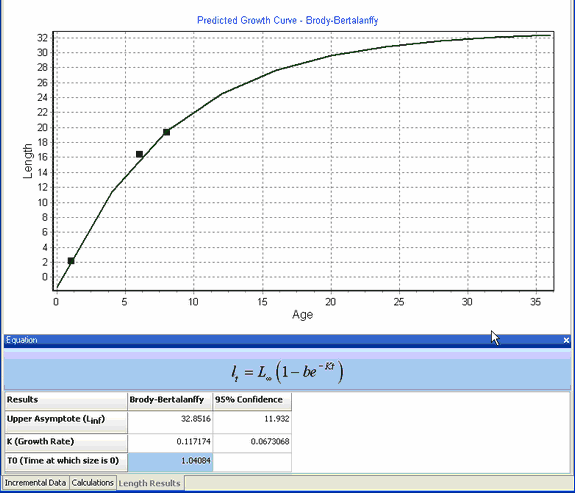
Once the data set has been opened, Growth II will immediately fit a von Bertalanffy growth curve to the data and plot the result.
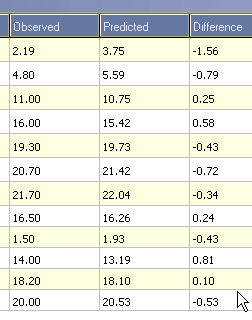
A brief glance at the grid below shows that the von Bertalanffy upper asymptote estimate has an estimate of 32.85 with 95% confidence intervals of 11.92. This suggests a rather poor fit. This is conformed by clicking on the Calculations tab and examining the differences between the observed and predicted values.
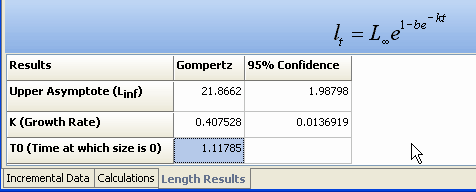
From the Incremental drop-down now choose the Gompertz option
The results are immediately displayed and the plot looks like a better fit. More importantly the confidence intervals on the parameter estimates are far smaller. For the asymptote, the 95% confidence intervals are only 1.98 compared with 11.932 for the von Bertalanffy. The Gompertz is clearly the better model, as it should be as the data was generated from a Gompertz curve with an asymptote of 21.9.
The superiority of the Gompertz over the von Bertalanffy is is also reflected in the differences between the observed and predicted on the Calculations tab.
You can also try a logistic fit which will give a poor fit to the data.
|