![]() Cluster analysis
Cluster analysis
|
|
Top Previous Next |
|
When numbers of sites or habitats are to be compared, the similarity measures offered by CAP can form the basis of cluster analysis, which seeks to identify groups of sites, or stations that are similar in their species composition.
Classification methods comprise two principal types, hierarchical, where objects are assigned to groups that are themselves arranged into groups as in a dendrogram, and non-hierarchical, where the objects are simply assigned to groups. The methods are further classified as either agglomerative, where the analysis proceeds from the objects by sequentially uniting them, or divisive, where all the objects start as members of a single group which is repeatedly divided. For computational and presentational reasons hierarchical-agglomerative methods are the most popular.
The basic computational scheme used in cluster analysis can be illustrated using single linkage cluster analysis as an example. This is the simplest procedure and consists of the following steps.
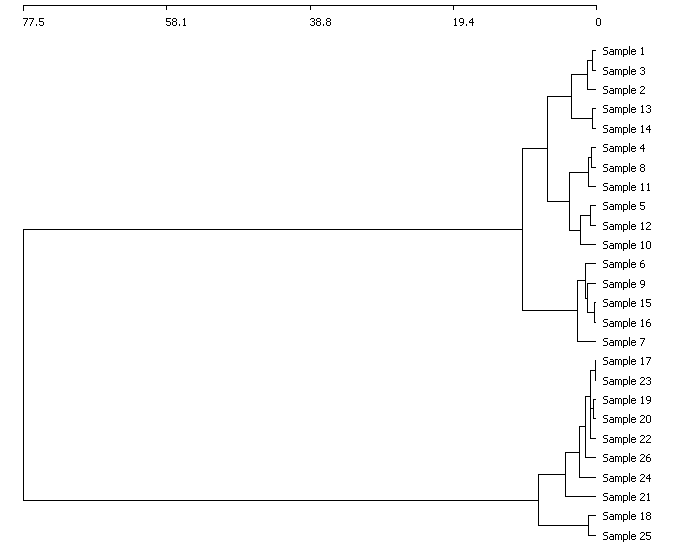
The results from a cluster analysis are usually presented in the form of a dendrogram:
The problem with all classification methods is that there can be no objective criteria of the best classification; indeed even randomly-generated data can produce a pleasing and convincing dendrogram. Always consider carefully whether the groupings identified seem to make sense and reflect some feature of the natural world.
If you wish to use R see Run R code
|